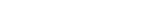Three services working together — a web interface your team uses, a security layer that governs access, and an AI engine that gets smarter with every interaction.
Request is analyzed — simple greeting or complex analysis?
Automatically picks the right AI model. Simple = fast. Complex = powerful.
Searches knowledge base, memory, connected tools, and web as needed.
Response flows back word-by-word in real time. No waiting.
Most AI tools forget everything between conversations. Osiris builds institutional memory — policies, preferences, projects, and people.
Organization-wide policies, SOPs, compliance requirements
Goals, timelines, key decisions, stakeholder contacts
Personality, expertise area, preferred resources
Role, expertise, communication preferences
Personal notes, reminders, draft ideas
Each assistant comes with Memory OS — it learns your policies, remembers your context, and connects to your tools.
Osiris never takes action without your approval. Read operations happen instantly. Write operations always pause for confirmation.
Osiris dynamically manages conversation context — keeping what matters, compressing what doesn’t, and optimizing costs automatically.
Under 10 messages — full history is used. The AI has complete context of everything discussed.
Up to 30 messages — recent messages plus key decision points are kept. Older messages are summarized.
30+ messages — sliding window with semantic retrieval. The AI finds relevant past messages when needed.
Very long sessions — AI-generated summaries replace old messages. Key facts preserved, noise removed.
System instructions, policies, and document knowledge are cached between messages. You only pay for what’s new — not for what the AI already knows.
Verify the organization has available credits before processing.
Classify intent and route to the optimal model: lightweight for simple tasks, powerful for complex analysis. Cost-optimized automatically.
ReAct loop: reason, call tools (MCP connectors, vector search, memory, DB), get results, reason again.
Write actions pause for approval. Response streams word-by-word via SSE. Memory extracted in background.
Automatically picks the right AI model for each request. Simple questions get fast, inexpensive answers. Complex analysis gets powerful models.
Answers appear word-by-word as they’re generated, just like a human typing. No waiting for the full response.
Upload company documents and search by meaning, not keywords. Ask “What was our approach to X?” and it finds the answer.
Transparent credit system. Every interaction tracked. Prompt caching reduces costs by up to 90% for routine operations.
Every employee gets AI appropriate to their role. Granular permissions: guest, user, manager, administrator.
Every interaction logged with complete visibility. Who asked what, when, and what was actioned — all traceable.
Start free and deploy AI across your company in 4 weeks.
Deploy interactive AI assistants for customer-facing needs AND autonomous agentic workflows for background automation - all in one secure, enterprise platform.