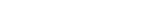Tri servisa rade zajedno — web interfejs koji vaš tim koristi, bezbednosni sloj koji upravlja pristupom, i AI motor koji postaje pametniji sa svakom interakcijom.
Zahtev se analizira — jednostavan pozdrav ili složena analiza?
Automatski bira pravi AI model. Jednostavno = brzo. Složeno = moćno.
Pretražuje bazu znanja, memoriju, povezane alate i web po potrebi.
Odgovor se vraća reč po reč u realnom vremenu. Bez čekanja.
Većina AI alata zaboravlja sve između razgovora. Osiris gradi institucionalno pamćenje — procedure, preferencije, projekte i ljude.
Procedure cele organizacije, SOP-ovi, zahtevi usklađenosti
Ciljevi, rokovi, ključne odluke, kontakti zainteresovanih strana
Ličnost, oblast ekspertize, preferirani resursi
Uloga, ekspertiza, preferencije komunikacije
Lične beleške, podsetnici, nacrti ideja
Svaki asistent dolazi sa Memory OS — uči vaše procedure, pamti kontekst i povezuje se sa vašim alatima.
Osiris nikada ne preduzima akciju bez vašeg odobrenja. Operacije čitanja se dešavaju odmah. Operacije pisanja uvek čekaju potvrdu.
Osiris dinamički upravlja kontekstom razgovora — čuva ono što je važno, kompresuje ono što nije, i automatski optimizuje troškove.
Under 10 messages — full history is used. The AI has complete context of everything discussed.
Up to 30 messages — recent messages plus key decision points are kept. Older messages are summarized.
30+ messages — sliding window with semantic retrieval. The AI finds relevant past messages when needed.
Very long sessions — AI-generated summaries replace old messages. Key facts preserved, noise removed.
System instructions, policies, and document knowledge are cached between messages. You only pay for what’s new — not for what the AI already knows.
Verify the organization has available credits before processing.
Classify intent and route to the optimal model: lightweight for simple tasks, powerful for complex analysis. Cost-optimized automatically.
ReAct loop: reason, call tools (MCP connectors, vector search, memory, DB), get results, reason again.
Write actions pause for approval. Response streams word-by-word via SSE. Memory extracted in background.
Automatically picks the right AI model for each request. Simple questions get fast, inexpensive answers. Complex analysis gets powerful models.
Answers appear word-by-word as they’re generated, just like a human typing. No waiting for the full response.
Upload company documents and search by meaning, not keywords. Ask “What was our approach to X?” and it finds the answer.
Transparent credit system. Every interaction tracked. Prompt caching reduces costs by up to 90% for routine operations.
Every employee gets AI appropriate to their role. Granular permissions: guest, user, manager, administrator.
Every interaction logged with complete visibility. Who asked what, when, and what was actioned — all traceable.
Start free and deploy AI across your company in 4 weeks.
Deploy interactive AI assistants for customer-facing needs AND autonomous agentic workflows for background automation - all in one secure, enterprise platform.